TensorRT Playground
TensorRT Playground
Description:
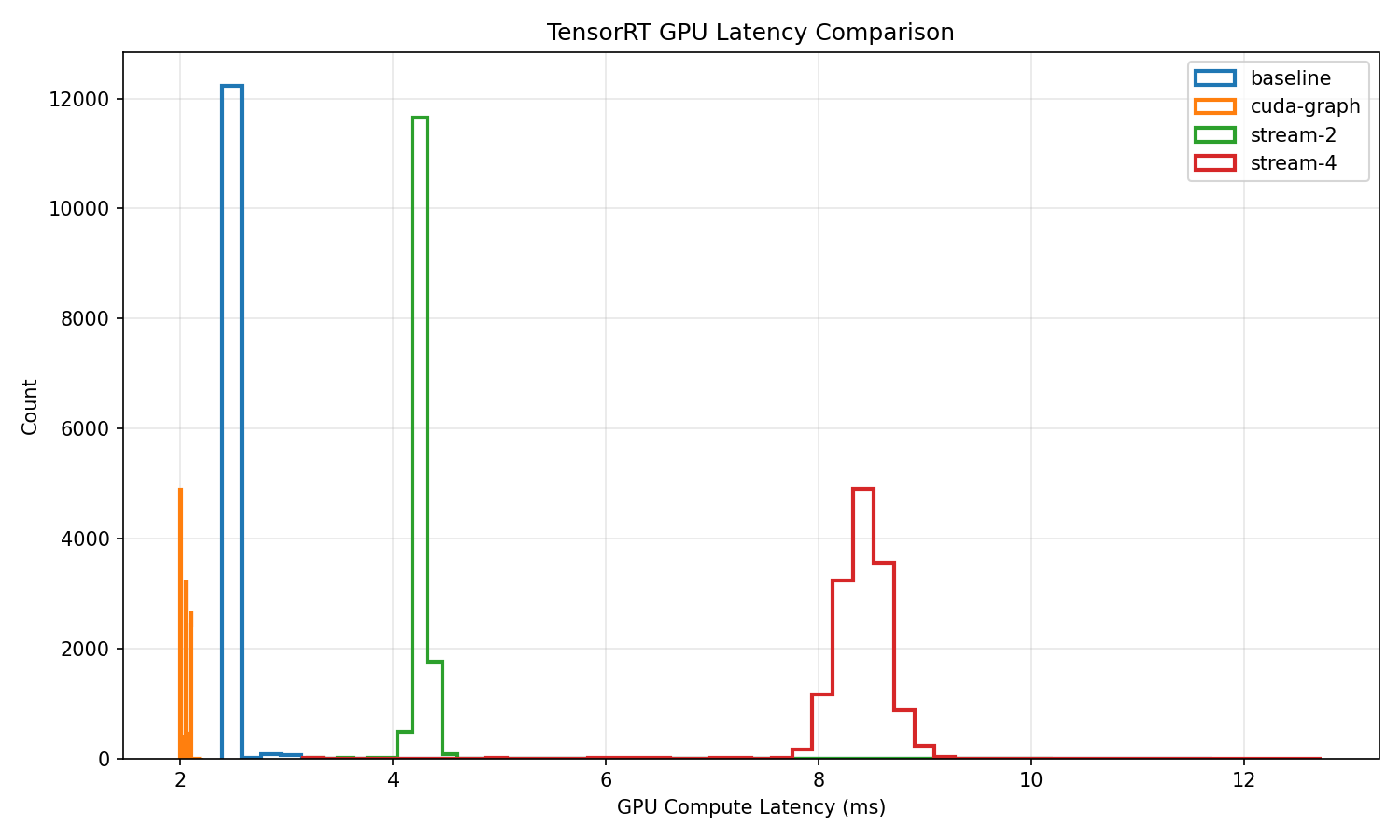
This project is a deep dive into high-performance inference optimization on NVIDIA Jetson Orin Nano using TensorRT. I exported a ResNet-50 model to ONNX, built optimized FP16 TensorRT engines, and systematically benchmarked inference performance under multiple execution configurations including baseline execution, CUDA Graphs, and multi-stream scheduling. Using TensorRT’s detailed timing traces, I extracted per-inference GPU compute latency and analyzed throughput, average latency, and tail latency (p90/p99) across more than 13,000 runs. The results were visualized with latency histograms and comparison plots to highlight variance reduction and performance tradeoffs introduced by different optimization techniques. This project demonstrates practical skills in embedded GPU performance engineering, model deployment, and low-level inference profiling on edge AI hardware.