Jetson Orin Nano Local GPT
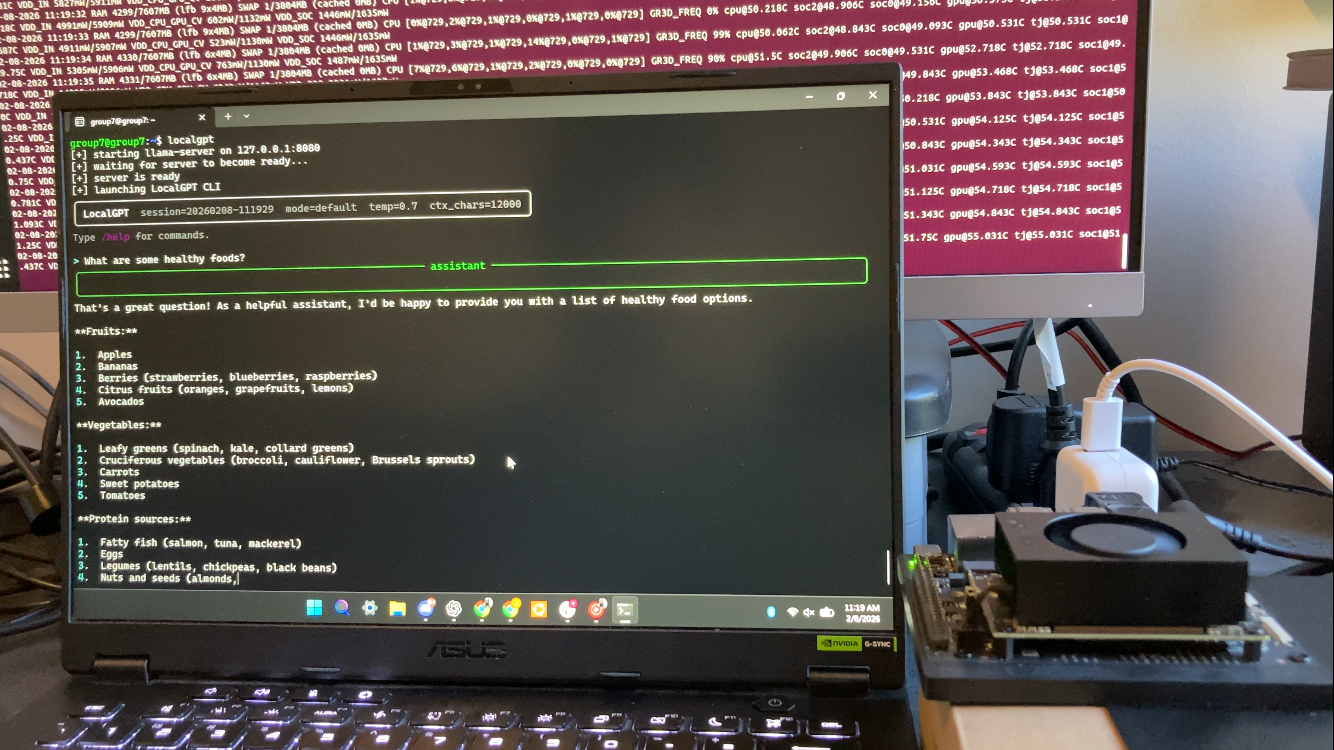
Jetson Orin Nano Local GPT
Description:
LocalGPT on Jetson Orin Nano is a fully offline, GPU-accelerated large language model system built for edge deployment. The project uses llama.cpp with CUDA acceleration to run a Llama 3.2 3B GGUF model entirely on an NVIDIA Jetson Orin Nano, providing an interactive, ChatGPT-style terminal interface with real-time streaming responses, persistent chat sessions, and configurable prompt modes. The system is designed as a production-ready application, featuring automatic server startup, systemd integration, and robust process management, demonstrating practical experience in embedded Linux, GPU-accelerated inference, and end-to-end AI system integration without reliance on cloud services.