FPGA 2D Convolution
FPGA 2D Convolution
Description:
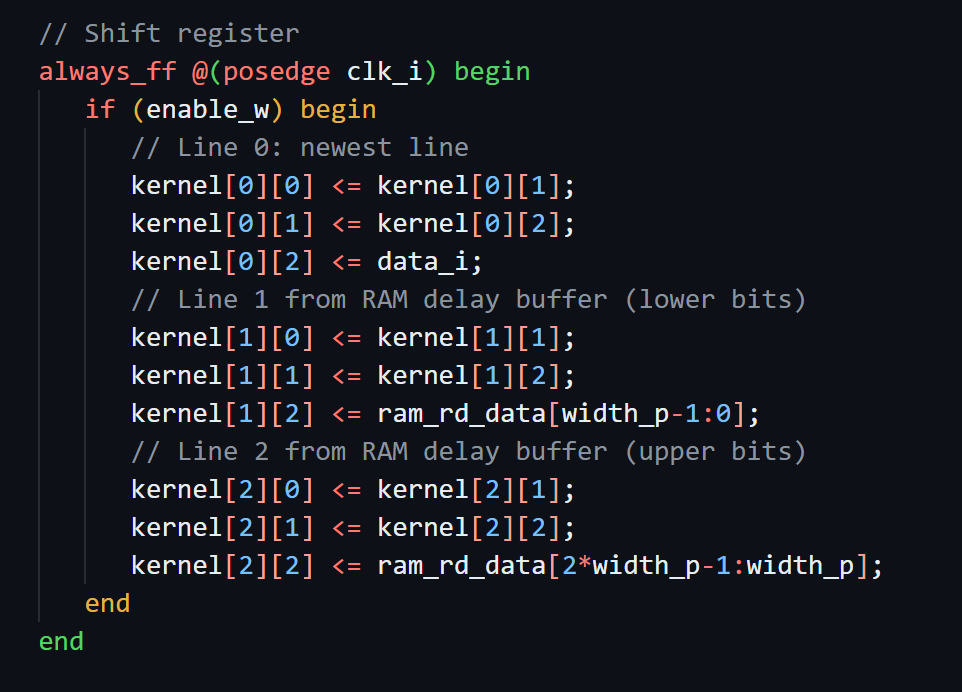
I designed and implemented a hardware-efficient 2D convolution module in SystemVerilog using a ready/valid streaming interface. The module applies a 3×3 convolution kernel to a pixel stream, replacing a naïve shift-register implementation with synchronous RAM-based line buffers to enable FPGA synthesis. By structuring the design as sliding window convolution using shift registers for horizontal taps and RAM delay buffers for vertical taps, the design efficiently maps to on-chip block RAM resources. I verified correctness using simulation with Verilator and Icarus Verilog, ensured lint compliance, and demonstrated that the design synthesizes to the expected number of RAM instances on the FPGA. This module forms the foundation for real-time image processing acceleration.