DSP Arithmetic Design
DSP Arithmetic Design
Description:
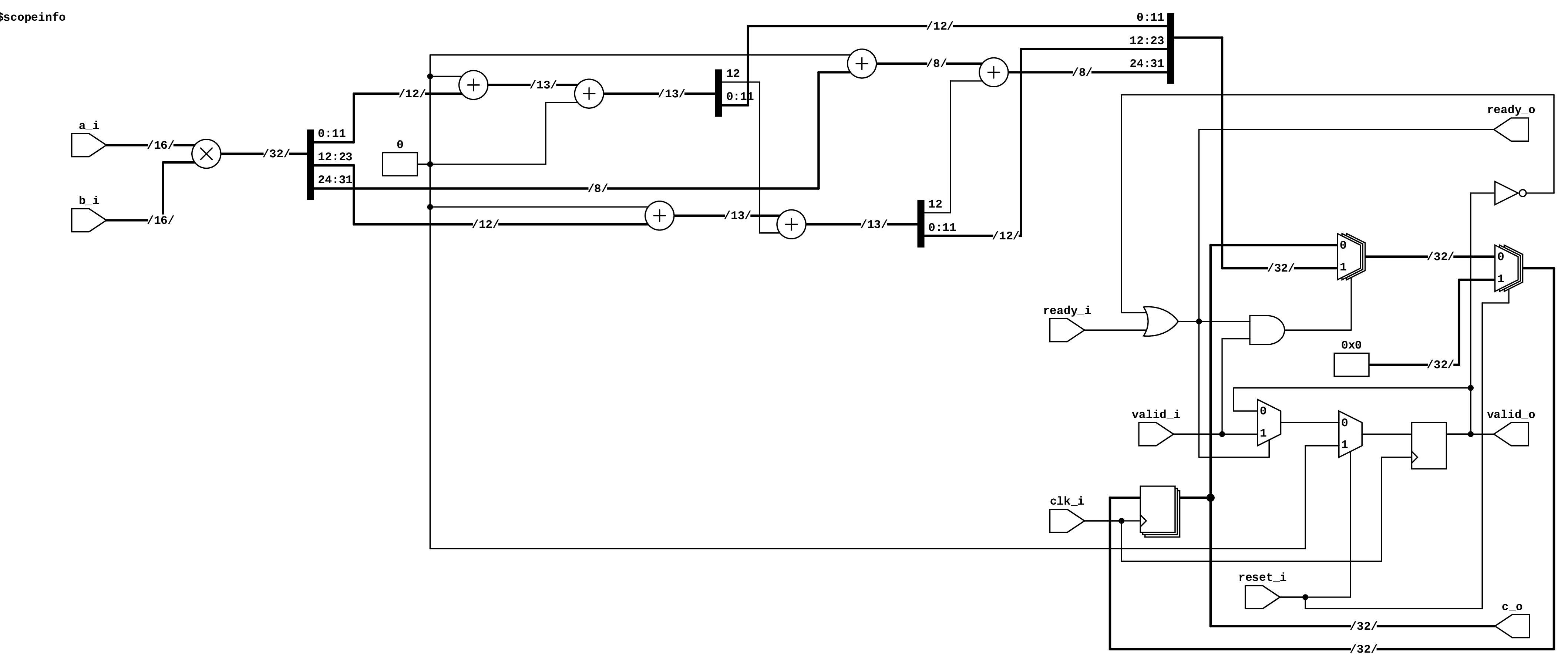
In this lab, I implemented high-speed arithmetic modules using Xilinx DSP48E1 primitives to explore optimized hardware design beyond behavioral Verilog synthesis. I first created a pipelined elastic adder and multiplier using standard Verilog operators to establish functional behavioral models and verify proper ready/valid handshake operation. I then replaced these arithmetic operators with the Xilinx DSP48E1 IP core, configuring its internal signals and parameters to perform efficient multiplication and addition with single-cycle latency. By leveraging the DSP48E1’s internal pipeline registers and built-in hardware capabilities, I achieved fully pipelined, high-performance designs that synthesized to a single DSP block each, without requiring external datapath registers. This project demonstrated practical experience in integrating vendor-optimized IP for arithmetic acceleration on FPGA architectures.