CUDA Microbench
CUDA Microbench
Description:
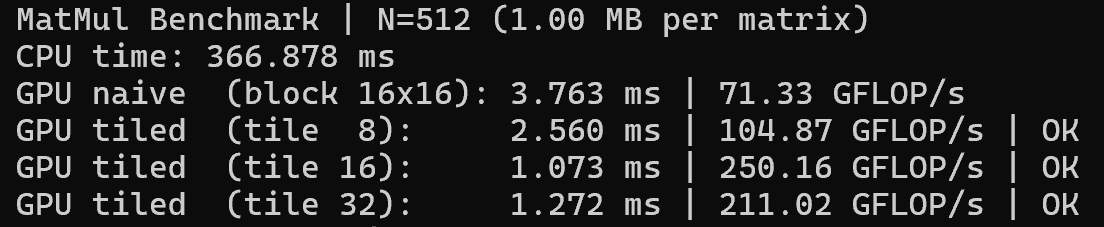
This project investigates low-level GPU performance and energy efficiency on the NVIDIA Jetson Orin Nano by designing and benchmarking custom CUDA kernels rather than relying on prebuilt frameworks. I implemented vector addition and matrix multiplication kernels from scratch, including both naive global-memory and shared-memory tiled matrix multiply, to study how thread organization, memory hierarchy, and tiling strategies impact execution. By sweeping block sizes and tile dimensions, I identified an optimal 16×16 shared-memory tile that maximized occupancy and minimized global memory traffic, achieving a 2.2× speedup over the naive GPU implementation and over 240× speedup compared to a CPU baseline for a 512×512 matrix. Performance was quantified in GFLOP/s, and power consumption was measured directly on the device using tegrastats, allowing calculation of performance-per-watt on real embedded hardware. The optimized kernel sustained approximately 250 GFLOP/s at an average board power of ~6.3 W, corresponding to nearly 40 GFLOP/s/W, demonstrating how memory-aware kernel design enables high computational efficiency on edge-class GPUs under strict power constraints.